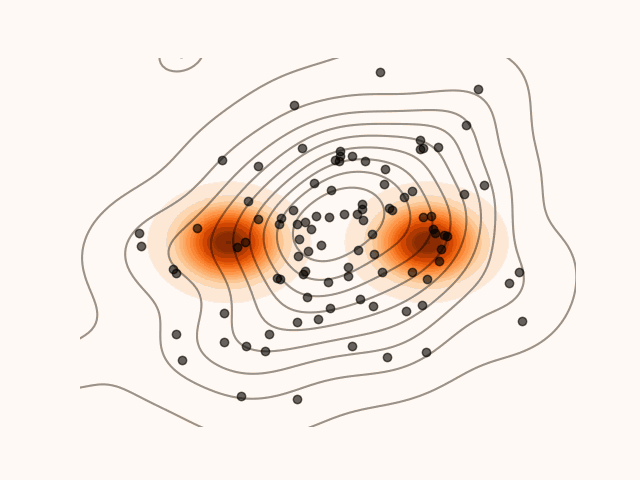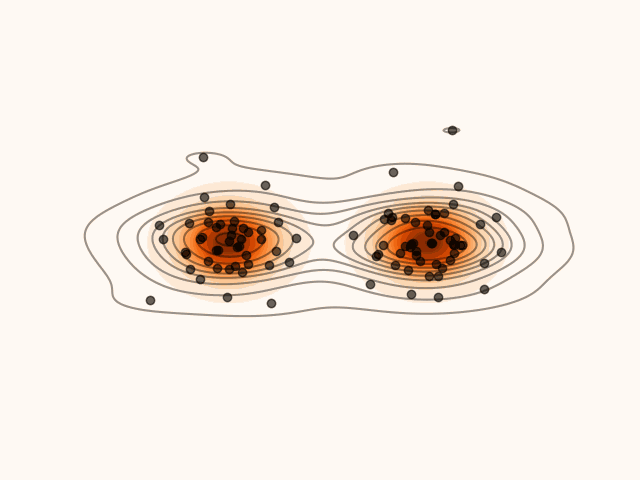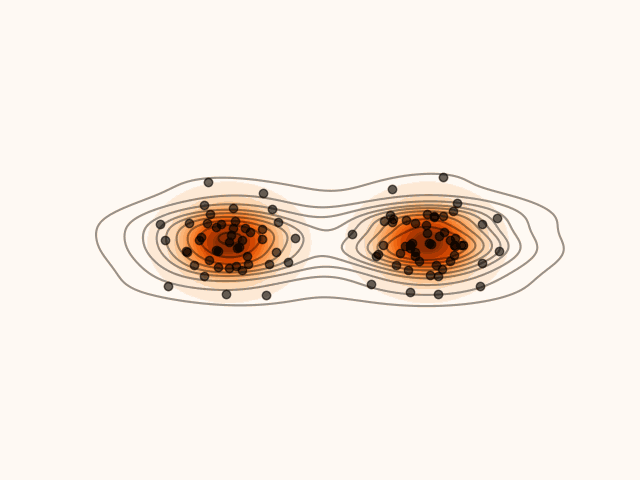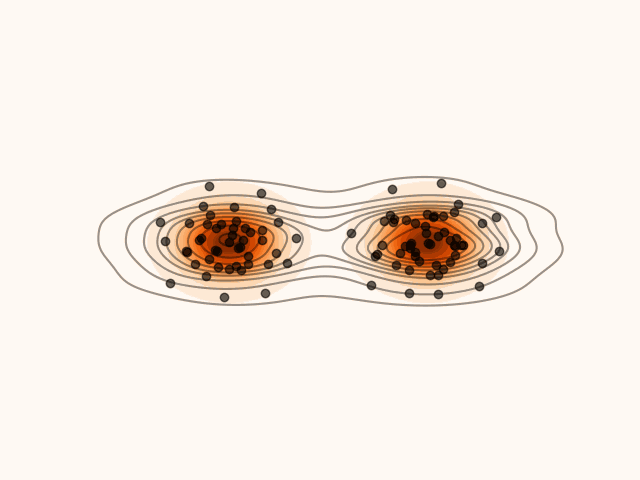
In this section, we derive a closed-form expression for the density induced by Stein Variational Gradient Descent (SVGD) at every sampling step.
SVGD can be viewed as iteratively transporting an initial distribution q0 through a sequence of smooth maps. It follows from optimal transport theory (Villani, 2009) that, under mild regularity assumptions, successive transport maps can transform a simple initial distribution into one that approximates arbitrarily complex target distributions. Consequently, after L SVGD updates, the particles {xiL}i=0M−1 can be regarded as samples from a distribution qL that closely approximates the target p.
Figure 1:Density’ evolution starting from q0 and following the SVGD velocity field.
Suppose that, after l SVGD steps, the particle xl is distributed according to ql.
Then, using the change of variable formula for densities (CVF), the distribution of xl+1=xl+ϵϕ(xl), where ϕ is the SVGD velocity field, is:
However, to apply the CVF, the SVGD transformation must be invertible.
To ensure this, MET-SVGD adapts a sufficient conditions for the invertibility of transformations of the form f(x)=x+g(x) from Behrmann et al. (2019) to SVGD.
Namely, f(xl)=xl+ϵϕ(xl) is invertible if ϵsupxl∣∣∇xlϕ(xl)∣∣2<1, where ∣∣∇xlϕ(xl)∣∣2 denotes the spectral norm of ∇xlϕ(xl).
In practice, it is easier to work with the log of the density, also called the log-likelihood:
Unfortunately, this expression involves the log of the determinant of a jacobian, which is expensive to compute.
To avoid this, under the condition
ϵ∣λmax(∇xlϕ(xl))∣<1,
MET-SVGD accurately estimates
log∣∣det(I+ϵ∇xlϕ(xl))∣∣
by
ϵTr(∇xlϕ(xl)),
giving:
logql+1(xl+1)≈logql(xl)−ϵTr(∇xlϕ(xl)).
For samples {xil}i=0M−1∼ql, the trace term evaluated at xil is:
When κ is the RBF kernel, the first term in the above expression can be efficiently computed using only vector dot products.
However, the second term is computationally expensive because it involves computing the trace of a hessian, which has O(D2) complexity.
One way to altogether bypass computing this term is to estimate the expectation in ϕ(xil) using {xil}i=0M−1−{xil}.
However, this turns out to be suboptimal in the finite particle case.
Instead, MET-SVGD efficiently estimates it as:
The correctness of the previous derivation depends on two conditions:
ϵsupxl∣∣∇xlϕ(xl)∣∣2<1 to ensure that the SVGD transformation is invertible
ϵ∣λmax(∇xlϕ(xl))∣<1 for the approximation of log∣∣det(I+ϵ∇xlϕ(xl))∣∣ to be accurate
While these are separate conditions, they can be unified by considering the order relation between the spectral norm of a real-valued square matrix A and the magnitude of λmax(A).
According to Wolkowicz & Styan (1980), for A∈Rd×d:
∣λi(A)∣≤σi(A)≤Tr(A⊤A)∀i∈[1…d],
where λi(A) and σi(A) are the i-th eigenvalue and singular value of A, respectively.
Given that ∣∣∇xlϕ(xl)∣∣2=σmax(∇xlϕ(xl)), we have:
Therefore, in order to satisfy both conditions, it is sufficient to choose the step-size such that:
ϵ<(xlsupTr(∇xlϕ(xl)⊤∇xlϕ(xl)))−1.
Note that
Tr(∇xlϕ(xl)⊤∇xlϕ(xl))
can be efficiently computed using only vector dot products and first-order derivatives, similarly to
Tr(∇xlϕ(xl)).
And, in practice, MET-SVGD solves supxl by taking the maximum over particles {xil}i=0M−1 at iteration l.