Problem Setup¶
We consider a target density known only up to normalization
where is intractable. Our objective is to approximate and estimate functionals of , particularly its entropy .
Problem Significance¶
Target distributions known only up to a normalization constant arise throughout machine learning. A prominent example is Maximum-Entropy Reinforcement Learning (MaxEnt RL), which augments the standard reinforcement learning objective
with an entropy regularization term,
where denotes the policy entropy and controls the reward-entropy trade-off.
Without the entropy term, the optimal solution is a deterministic policy that selects a single highest-return action in each state. In contrast, maximizing the entropy-regularized objective yields a stochastic policy that assigns probability mass to multiple high-return actions. In fact, the optimal MaxEnt policy takes the form
which is an energy-based distribution over the Q-values with an intractable normalization constant.
The resulting stochasticity provides a significant robustness advantage. Rather than committing to a single trajectory, the agent learns a distribution over multiple high-reward behaviors. Consequently, if the environment changes at test time, the policy can exploit alternative strategies that were also assigned non-negligible probability during training.
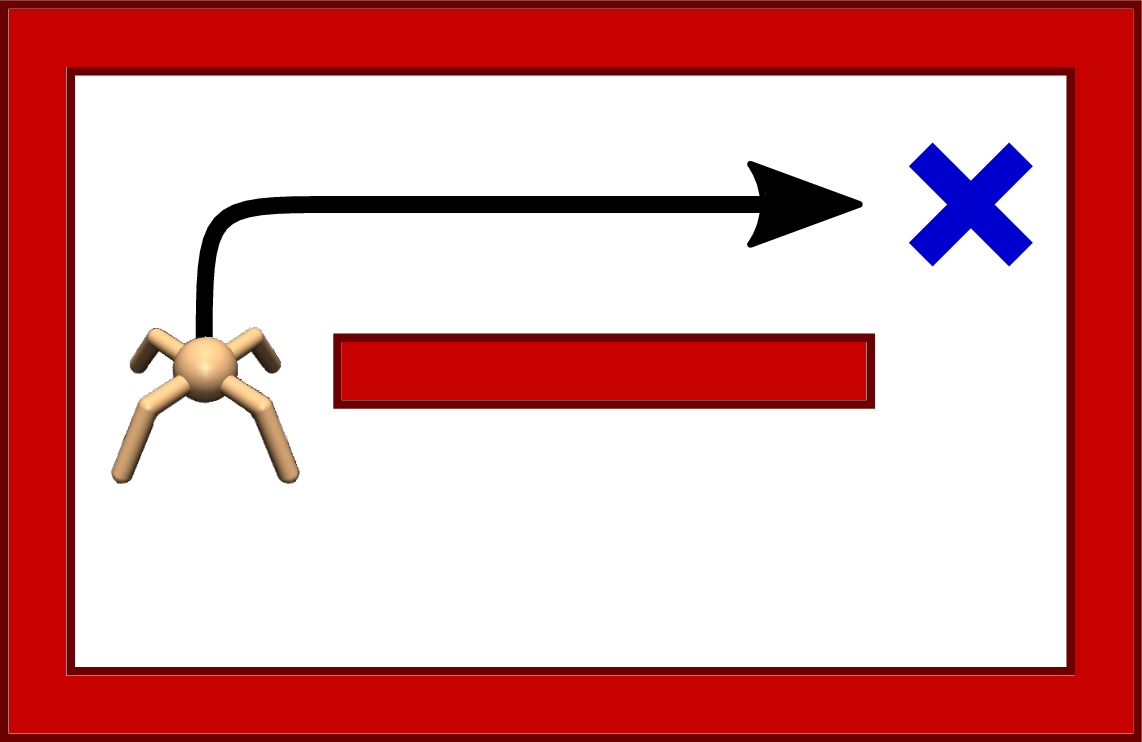
(a)Environment at train time (No obstacles).
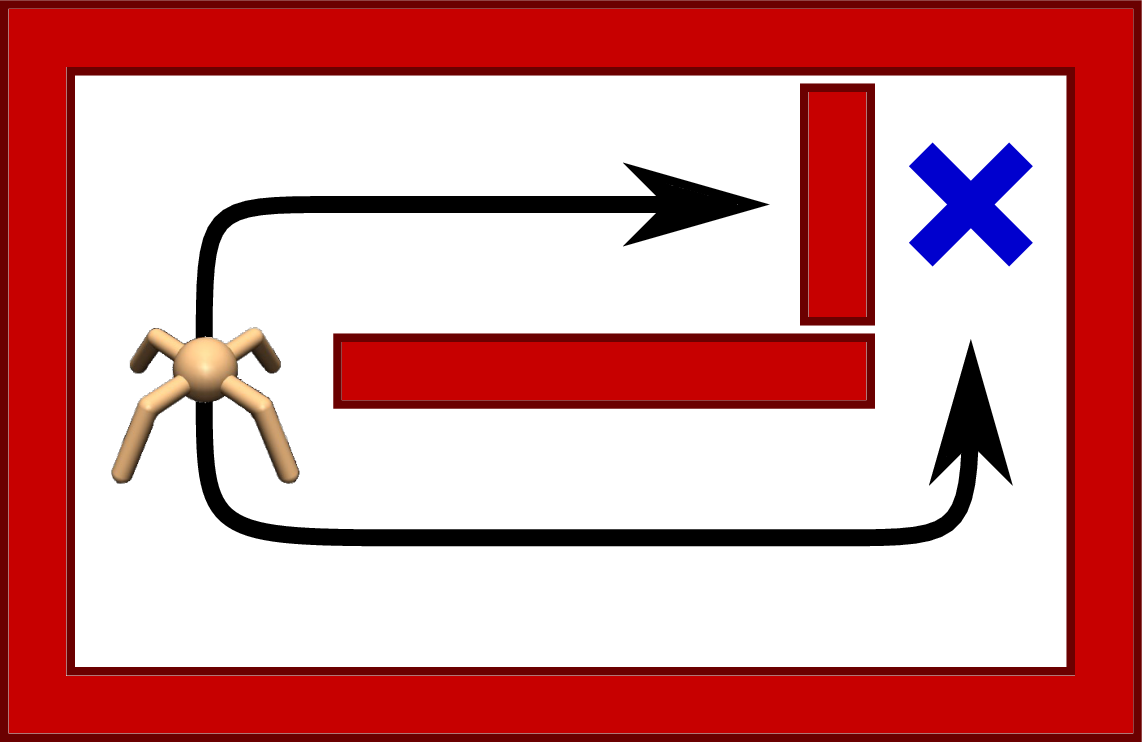
(b)Environment at test time.
Figure 1:A robot navigating a maze. Ref: https://
The figure below illustrates this effect. A deterministic policy is likely to fail because it has committed to a single behavior. In contrast, a maximum-entropy policy can adapt by exploiting an alternative route that was already represented in its action distribution.
This robustness comes at a cost: evaluating the MaxEnt objective requires estimating the entropy
yet is only available through an unnormalized density.
The Challenge¶
The primary challenge is that the normalization constant is unknown, making direct evaluation of
intractable. While can be computed analytically for simple distributions such as Gaussians, it is generally unavailable for the complex, high-dimensional distributions encountered in modern machine learning.
Existing approaches fall into two broad categories:
Sampling-based methods (e.g., HMC, Langevin dynamics, SVGD) directly leverage the unnormalized density through its score function to generate samples from the target distribution. These samples can subsequently be used to estimate and related quantities, for example via importance sampling. However, such estimators often suffer from high variance in high dimensions and may require substantial computation to obtain high-quality samples.
Variational inference methods approximate with a tractable distribution , enabling efficient sampling and density evaluation. This includes expressive families such as normalizing flows, which are however notoriously hard to optimize with gradient descent methods.
Ideally, we seek a method that constructs an approximation that:
accurately captures complex, multimodal target distributions,
directly leverages the unnormalized density ,
enables efficient sampling,
supports accurate entropy estimation and
remains computationally tractable and scalable.
MET-SVGD¶
Metropolis-Hastings Stein Variational Gradient Descent (MET-SVGD) addresses the above challenges by deriving a tractable density representation for Stein Variational Gradient Descent (SVGD) Liu & Wang, 2016. This enables direct entropy estimation while retaining SVGD’s ability to draw samples from complex target distributions.
More broadly, MET-SVGD unifies three major paradigms for approximate inference: Stein Variational Gradient Descent (SVGD), parametric variational inference (P-VI), and Metropolis-Hastings (MH). As a result, it inherits key advantages from each:
SVGD: expressive nonparametric approximation, efficient particle usage, and principled convergence diagnostics;
P-VI: scalability through parameterized samplers and efficient amortized inference;
MH: asymptotic correctness and convergence guarantees.
A key contribution of MET-SVGD is that it enables SVGD to scale to high-dimensional distributions while preserving computational efficiency and multimodal expressivity.
Furthermore, MET-SVGD replaces expensive hyperparameter search with end-to-end optimization of sampler parameters through KL-divergence minimization, enabling automatic adaptation of the inference procedure to the target distribution.
Finally, MET-SVGD can be interpreted as a full-rank normalizing flow whose layers are induced by successive SVGD updates. Unlike conventional flows with a fixed depth, the number of transformations is determined adaptively through a convergence criterion, yielding a flexible and highly expressive density model.
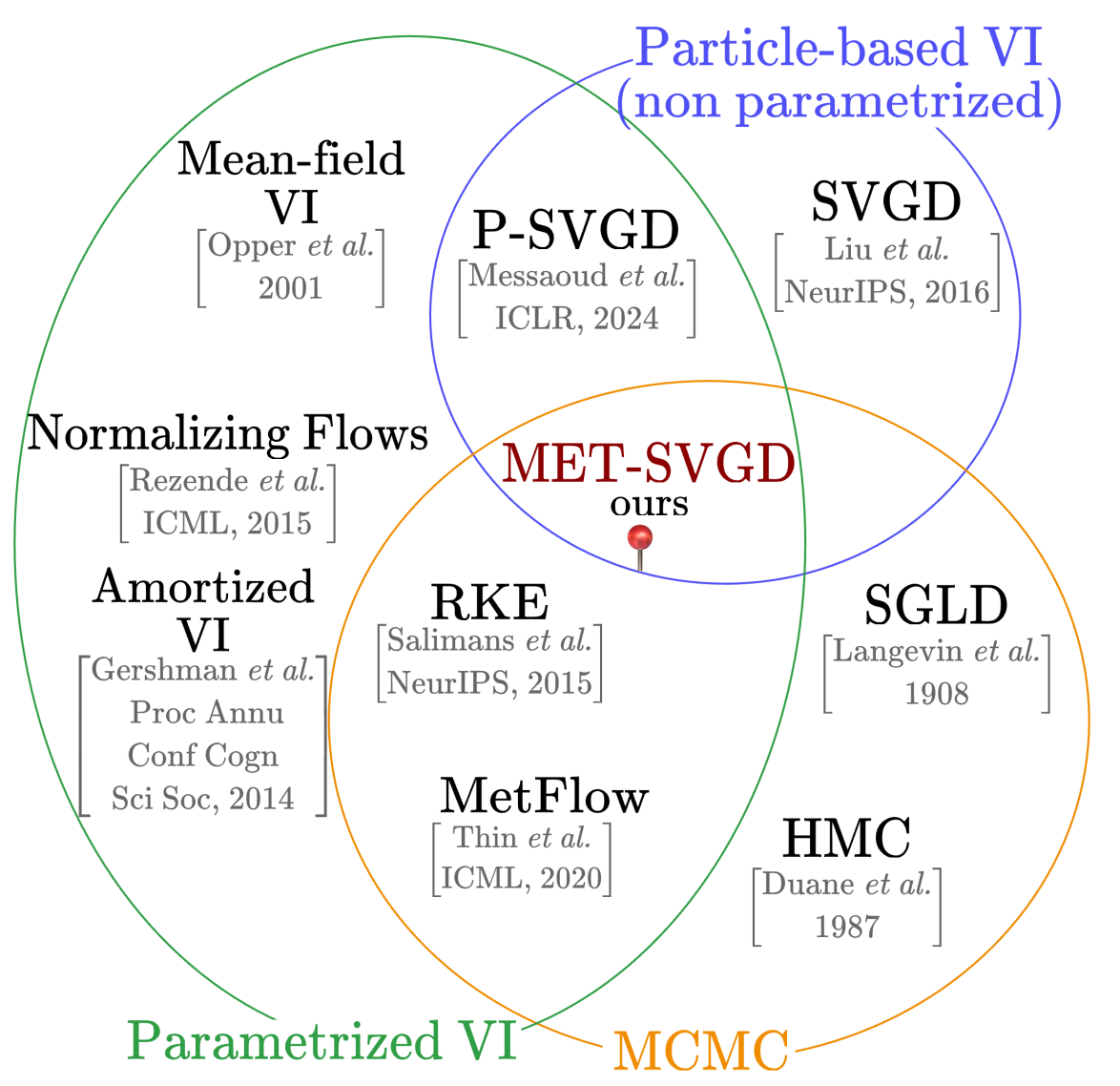
Figure 2:MET-SVGD bridges the gap between P-VI, SVGD, and MCMC methods.
Table 1:MET-SVGD inherits the advantages of different approximate inference methods
| P‑VI | MCMC | SVGD | P‑SVGD | MET‑SVGD | |
|---|---|---|---|---|---|
| Expressivity | ✗ | ✓ | ✓ | ✓ | ✓✓ |
| Convergence Detection | ✓ | ✗ | ✓ | ✓ | ✓ |
| Convergence Guarantees | ✗ | ✓ | ✗ | ✗ | ✓ |
| Sampling Efficiency | ✓ | ✗ | ✓ | ✓ | ✓ |
| Tractable Entropy | ✓ | ✗ | ✗ | ✓ | ✓ |
| Parameter Efficiency | ✓ | — | — | ✓✓ | ✓✓ |
- Liu, Q., & Wang, D. (2016). Stein variational gradient descent: A general purpose bayesian inference algorithm. NeurIPS.